
https://dacon.io/competitions/official/236092/overview/description
1은 코랩 환경설정과 데이터 전처리에 대해 다룰 예정
참고로 학교에서 컴퓨터를 지원해줘서 아나콘다를 사용했는데 그건 팀원중에 컴공 팀원분이 해줘서 난 잘 모르고,,, 나는 코랩을 이용하여 했다.
단점은 코랩은 구글에서 gpu를 지원해주는거라 일정시간만 지원해주는데 이게 하루에 반나절정도를 사용하면 끊기고 하루정도 쉬어야 다시 돌아간다.
그래서 주기적으로 저장해주어야 하고 화날수있는걸 감당할 멘탈과 수많은 구글계정, 구글계정도 전화번호를 너무 많이 사용하면 끊겨서 전화번호를 빌려줄 인맥이 필요하다.
-colab 기본 사용법
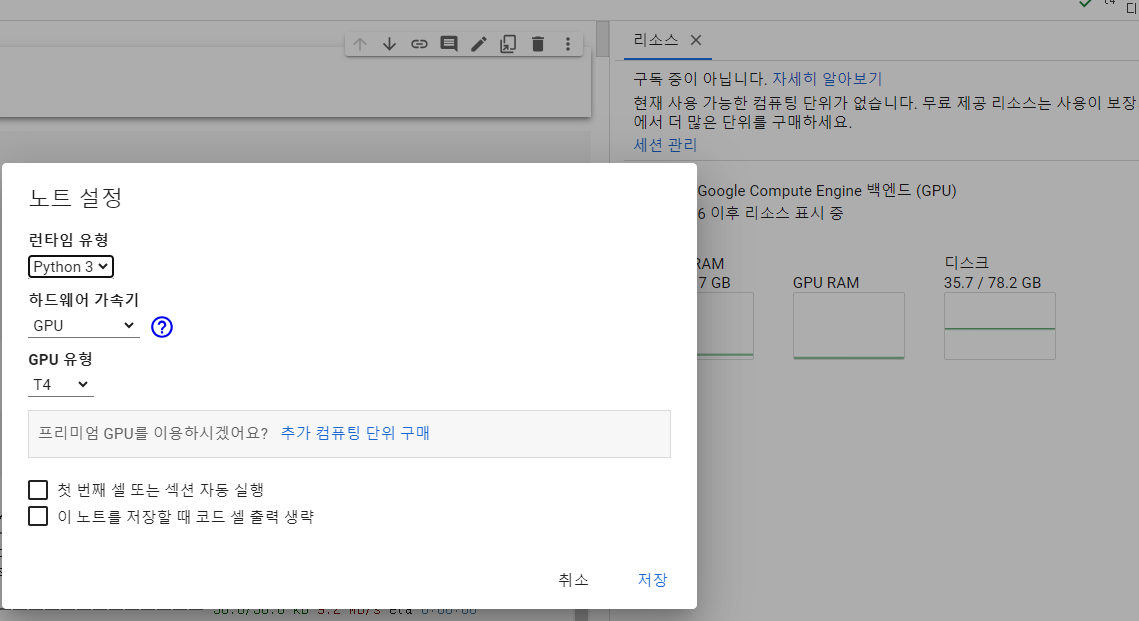
오른쪽 런타임 할당, 유형변경에서 하드웨어 가속기로 gpu연결 하기
gpu는 학습할때만 연결해주자.
대회든 어디든 데이터는 보통 압축해서 zip파일로 준다.
압축한 데이터를 구글 드라이브에 직접 넣어준다.
무조건 하나 zip파일은 넣어주는게 좋다. 이거 매번 직접 넣어주면 너무 오래걸려서 복장이 터진다.
그걸 다른계정에 공유해주면 그사람이 자기 드라이브에 바로가기로 넣어줄 수 있다.
그렇게 바로가기로 넣어주고 그때그때 런타임에 압축을 풀어 사용하는 걸 권한다.
이거 압축풀때 내 드라이브에 풀면 내 드라이브가 수많은 사진파일의 용량에 파묻혀 죽어버린다.
런타임 마다 풀어라.
아 본인도 결제해서 걍 한번 내 드라이브에 풀었는데 이거 직접 푼걸로 학습시키면 content에 런타임마다 하는것보다 학습이 더 오래걸리고 파일 가져오는것도 오래걸린다.
구글 드라이브 마운트
from google.colab import drive
drive.mount('/content/drive', force_remount=True)
#압축파일 풀 곳
%cd /content
#zip 경로
!unzip -qq /content/drive/MyDrive/ai_project_4-1/data.zip
%cd는 경로를 지정하는 코드이다. 그냥 앞으로도 경로 지정하고 싶을때 쓰면된다.
현경로 파악은 그냥 pwd 코드를 실행하면 보인다.
unzip을 통해 압축을 풀자.
경로는 왼쪽 폴더, 파일 우클릭을 하면 경로복사가 뜨니 쉽게 알수 있다.
시드 고정
import random
def seed_everything(seed):
random.seed(seed)
os.environ['PYTHONHASHSEED'] = str(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed(seed)
torch.backends.cudnn.deterministic = True
torch.backends.cudnn.benchmark = True
seed_everything(41) # Seed 고정
랜덤 변수의 숫자를 고정해준다.
똑같이 구현하고자 할 때 필요하니 팀원과 맞출 것
필요한거 import해주고 !pip으로 설치
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')할당한 gpu는 cuda로 사용할 수 있다.
gpu가 있는 경우에는 cuda를 사용하고 아닌경우 cpu를 사용하라는 뜻
DATA 분석
주어진 데이터 정보
- train_img [폴더]
- TRAIN_0000.png ~ TRAIN_7139.png
- 1024 x 1024
- test_img [폴더]
- TEST_00000.png ~ TEST_60639.png
- 224 x 224
- train.csv [파일]
- img_id : 학습 위성 이미지 샘플 ID
- img_path : 학습 위성 이미지 경로 (상대 경로)
- mask_rle : RLE 인코딩된 이진마스크(0 : 배경, 1 : 건물) 정보
- 학습 위성 이미지에는 반드시 건물이 포함되어 있습니다.
- 그러나 추론 위성 이미지에는 건물이 포함되어 있지 않을 수 있습니다.
- 학습 위성 이미지의 촬영 해상도는 0.5m/픽셀이며, 추론 위성 이미지의 촬영 해상도는 공개하지 않습니다.
- test.csv [파일]
- img_id : 추론 위성 이미지 샘플 ID
- img_path : 추론 위성 이미지 경로 (상대 경로)
- sample_submission.csv [파일] - 제출 양식
- img_id : 추론 위성 이미지 샘플 ID
- mask_rle : RLE 인코딩된 예측 이진마스크(0: 배경, 1 : 건물) 정보
- 단, 예측 결과에 건물이 없는 경우 반드시 -1 처리
이걸 하나의 zip파일로 준다.
train image 예시


test image


train 이미지 라벨링확인

사실 이 데이터 분석부터 중요하게 할 것
코드와 함께 보겠다.
대회에서 준 베이스라인코드, 우리가 구현한 코드를 함께 리뷰할 예정
RLE encoding, decoding 함수
# RLE 디코딩 함수
def rle_decode(mask_rle, shape):
s = mask_rle.split()
starts, lengths = [np.asarray(x, dtype=int) for x in (s[0:][::2], s[1:][::2])]
starts -= 1
ends = starts + lengths
img = np.zeros(shape[0]*shape[1], dtype=np.uint8)
for lo, hi in zip(starts, ends):
img[lo:hi] = 1
return img.reshape(shape)
# RLE 인코딩 함수
def rle_encode(mask):
pixels = mask.flatten()
pixels = np.concatenate([[0], pixels, [0]])
runs = np.where(pixels[1:] != pixels[:-1])[0] + 1
runs[1::2] -= runs[::2]
return ' '.join(str(x) for x in runs)주어진 csv의 라벨데이터를 다루는 방법이다.
RLE는 대충 0,1로 되어있는 데이터를 011101 이면 1로된 데이터만 픽셀 위치, 개수로 압축하는 기법이다.
따라서 인코딩할때는 쫙 펴서 똑같은 걸 만들어 한칸씩 미뤄 다른지점을 체크하여 압축한다.
디코딩 할때는 짝번 홀수번 끼리 묶어서 알맞은 자리에만 1을 넣어준다.
Dataset, Dataloader
class SatelliteDataset(Dataset):
def __init__(self, csv_file, transform=None, infer=False):
self.data = pd.read_csv(csv_file)
self.transform = transform
self.infer = infer
def __len__(self):
return len(self.data)
def __getitem__(self, idx):
img_path = self.data.iloc[idx, 1]
image = cv2.imread(img_path)
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
if self.infer:
if self.transform:
image = self.transform(image=image)['image']
return image
mask_rle = self.data.iloc[idx, 2]
mask = rle_decode(mask_rle, (image.shape[0], image.shape[1]))
if self.transform:
augmented = self.transform(image=image, mask=mask)
image = augmented['image']
mask = augmented['mask']
return image, masktrain_dataset = SatelliteDataset(csv_file='train.csv', transform=transform)
train_dataloader = DataLoader(train_dataset, batch_size=16, shuffle=True, num_workers=2)데이터를 가져오는 코드, 대충 요약하면 train csv 파일을 읽어온다.
batch사이즈는 돌아가는 사양대로, 남들하는대로 설정해주고 학습할거니까 shuffle은 true로 하고 transform은 밑에서 후술 하겠다.
아무튼 정의한 transform으로 transform을 실행해준다.
학습할때 tqdm으로 가녀올건데 가져올때마다 데이터 일부를 떼어와서 처리한다.
자세한건 구글링
데이터 plot (matplot 이용)
import cv2
import matplotlib.pyplot as plt
%cd /content
test_data = pd.read_csv('test.csv')
%cd /content/drive/MyDrive/ai_project_4-1
submit1 = pd.read_csv('single_model_origin_interpolation.csv')
submit2 = pd.read_csv('single_model_origin_interpolation_tta.csv')
for i in range(60050,60080):
test_image_path = test_data['img_path'][i]
test_image = cv2.imread(test_image_path)
test_mask1 = rle_decode(submit1['mask_rle'][i], (224,224))
test_mask2 = rle_decode(submit2['mask_rle'][i], (224,224))
plt.figure(figsize=(10,10))
plt.subplot(131)
plt.imshow(test_image)
plt.axis("off")
plt.subplot(132)
plt.imshow(test_mask1)
plt.axis("off")
plt.subplot(133)
plt.imshow(test_mask2)
plt.axis("off")사실 훈련후 test이미지를 출력하기 위한 코드로 썼던 건데 조금만 변형해서 train이미지 , 라벨 출력에 사용하면 된다.
주어진 test csv에는 이미지 path가 주어져있다. range 범위의 csv파일 img_path에 맞는 이미지를 불러와서 1열에 출력해준다.
이에 맞는 라벨지를 decode하고 출력한다.
test_mask1 줄의 코드는 submit1의 csv의 i번째 라벨지를 가져와서 (224,224)크기로 rle_decode한걸 할당하는 코드이다.
즉 라벨지를 출력한다.
출력 결과는
이미지60050 csv1 라벨60050 csv2 라벨60050이
이미지60051 csv1 라벨60051 csv2 라벨60051
-
-
-
주르륵이 될 것이다.

이렇게
데이터를 살펴보자
1.라벨링 확인
생각보다 이 정답 라벨링이 정확하게 되어있지 않은 경우가 많다.
우리의 train 데이터는 대략 7100장 정도였는데, 이정도면 다 훑을 수 있으니 다 살펴보고 잘못 표기된 이미지는 빼거나 크롭하여 사용하는게 낫다고 한다.
우리도 확인했을 때 이게 뭐야..? 싶은 라벨링 데이터가 있었는데 그걸 뺐었어야 한걸 너무 늦게 알아서 못했다...
그리고 테스트 이미지가 train이미지에 비해 굉장히 넓은 구역을 보여주고 있는데 애초에 1024,1024로 테스트에 비해 트레인 이미지가 크다.
2. 이미지 크기를 맞추기 위해 (탐지할 객체를 train - test 비슷한 크기로 맞춤) train을 잘라서 활용했다.
이는 굉장한 성능상승을 보여주었지만 random crop이든 center crop이든 모든 이미지를 쓰는게 아니라 부분, 확률적인 이미지를 사용하다 보니 데이터 손실을 일으키는 점이 단점이었다.
이는 sliding window, 즉 이미지를 순서대로 자르는 기법을 사용하면 되는데 우리는 transform 함수를 사용하여 train이미지를 가져올때 transform을 이용했기 때문에 위와 같은 방법이 힘들었다.
그냥 증강 하여 사용하는것도 하나의 방법.

이게 예전에 학습시킨다고 train이미지를 test처럼 돌려서 확인한건데 crop하면 아래에서 위처럼 잘린다.
즉 위처럼 학습시켜야 건물 인식을 잘한다.
transform = A.Compose(
[
#A.CenterCrop(224, 224, p=1),
A.RandomCrop(224, 224, p=1),
#A.HorizontalFlip(p = 0.5),
#A.IAAAdditiveGaussianNoise(p=0.2),
#A.IAAPerspective(p=0.5),
#A.OneOf([
#A.CLAHE(p=1),
#A.RandomBrightness(p = 1),
#A.RandomGamma(p = 1)
#], p = 0.5),
#A.OneOf([
#A.IAASharpen(p = 1),
#A.Blur(blur_limit=3, p=1),
#A.GaussianBlur(p = 1),
#A.MotionBlur(blur_limit=3, p=1),
#A.GaussNoise(p = 1)
#], p = 0.5),
#A.OneOf([
#A.RandomContrast(p=1),
#A.HueSaturationValue(p=1),
#], p = 0.5),
A.Resize(224, 224),
A.Normalize(),
ToTensorV2()
]
)
transform_test = A.Compose(
[
A.Resize(224, 224),
A.Normalize(),
ToTensorV2()
]
)transform을 정의하자.
train이미지에 여러가지 transform을 적용하여 다양한 상황을 학습하도록 하거나 데이터를 증강하는 효과를 낸다.
우리는 albumentations을 import하여 사용하였다.
기본적인 확률은 1로 지정되어있어 다 적용된다.
train은 다양하게 시도해보고 test이미지는 사이즈만 조절하였다.
normalize는 사진 픽셀 분포도를 조절해주는건데 원래 저렇게 기본값으로 돌렸었다.
근데 이게 유명한 imagenet의 분포도라 직접 자기의 데이터를 알아내서 넣어주는게 낫다고 한다.
우리도 바꿔주었다.
one of은 안에 있는 변형중 하나만 적용된다.
즉 one of 자체를 실행할지 말지는 그 one of의 p로 조정하고
안에 각각의 p는 정규분포화 되어 합이 1이 되도록 알아서 조절된다.
transform 종류는 albumentations 검색하면 라이브러리가 나오니 참고하시길
cutmix 기법
def cutmix(batch, alpha=1.0, p=0):
'''
alpha 값을 1.0으로 설정하여 beta 분포가 uniform 분포가 되도록 함으로써,
두 이미지를 랜덤하게 combine하는 Cutmix
'''
data, targets = batch
# cutmix 확률 설정
if np.random.random() > p:
return data, (targets, torch.zeros_like(targets), 1.0)
indices = torch.randperm(data.size(0))
shuffled_data = data[indices]
shuffled_targets = targets[indices]
lam = np.random.beta(alpha, alpha)
image_h, image_w = data.shape[2:]
cx = np.random.uniform(0, image_w)
cy = np.random.uniform(0, image_h)
w = image_w * np.sqrt(1 - lam)
h = image_h * np.sqrt(1 - lam)
x0 = int(np.round(max(cx - w / 2, 0)))
x1 = int(np.round(min(cx + w / 2, image_w)))
y0 = int(np.round(max(cy - h / 2, 0)))
y1 = int(np.round(min(cy + h / 2, image_h)))
data[:, :, y0:y1, x0:x1] = shuffled_data[:, :, y0:y1, x0:x1]
targets = (targets, shuffled_targets, lam)
return data, targets
class CutMixCollator:
def __init__(self, alpha, p):
self.alpha = alpha
self.p = p
def __call__(self, batch):
batch = torch.utils.data.dataloader.default_collate(batch)
batch = cutmix(batch, self.alpha, self.p)
return batchclass CutMixCriterion:
def __init__(self):
self.criterion = criterion
def __call__(self, preds, targets):
targets1, targets2, lam = targets
targets1 = targets1.unsqueeze(1)
targets2 = targets2.unsqueeze(1)
return lam * self.criterion(
preds, targets1) + (1 - lam) * self.criterion(preds, targets2)collator = CutMixCollator(alpha=1.0, p=0.5)
train_ds = SatelliteDataset(csv_file='train.csv', transform=transform)
train_dl = DataLoader(train_ds, batch_size=16, shuffle=True, num_workers=2, collate_fn = collator)
train_dl2 = DataLoader(train_ds, batch_size=16, shuffle=True, num_workers=2)
train_criterion = CutMixCriterion()
cutmix ver
train 돌리는 코드
import torch.optim as optim
optimizer = torch.optim.AdamW([dict(params=model.parameters(), lr=0.0001,weight_decay=1e-4)],)
#optimizer = AdamP(params=model.parameters(), lr=0.001, betas=(0.9, 0.999), weight_decay=1e-4)
# training loop
for epoch in range(20): # 10 에폭 동안 학습합니다.
model.train()
model.to('cuda')
epoch_loss = 0
for images, masks in tqdm(train_dl):
images = images.float().to(device)
targets1, targets2, lam = masks
masks = (targets1.float().to(device), targets2.float().to(device), lam)
optimizer.zero_grad()
outputs = model(images)
loss = train_criterion(outputs, masks)
loss.backward()
optimizer.step()
epoch_loss += loss.item()
%cd /content/drive/MyDrive
torch.save(model.state_dict(), f'single_model{epoch+1}.pth')
%cd /content
print(f'Epoch {epoch+1}, Loss: {epoch_loss/len(train_dl)}')원래 train코드에 넣는 변수만 다르다
train 코드는 다음 포스팅에 뜯어보겠지만 cutmix까지 넣었으니 참고용으로 올린다.
다음 포스팅은 모델 구현 코드로 찾아올게용